Build a website AI chatbot with n8n in 2026: RAG, lead capture, books calls
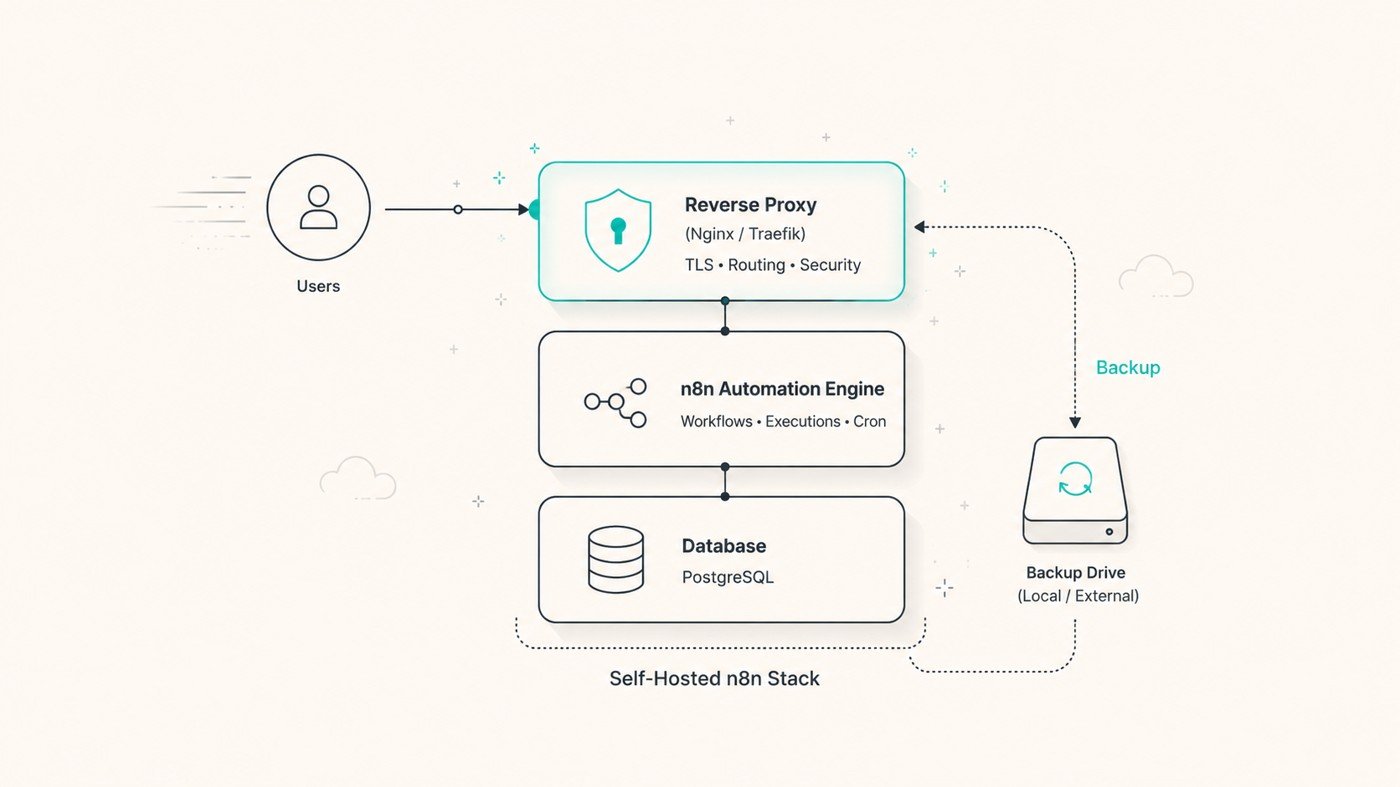
A website chatbot earns its keep only when it does three things: answers from your content (RAG), refuses to make things up, and turns a good conversation into a captured lead and a booked call. The stable 2026 build is two n8n pipelines, an ingest pipeline (crawl → chunk → embed → vector store) and a chat pipeline (webhook → retrieve → LLM → respond → capture). You are no longer locked to OpenAI: n8n has first-party nodes for GPT-4o, Claude, and Gemini, so pick the model per job and keep the workflow the same.
Most website chatbots fail one of two ways. The old kind is a decision-tree script with twelve canned buttons that never matches what the visitor actually typed. The new kind is a raw language model bolted to a chat bubble with no source of truth, confidently inventing a refund policy you don't have. A production chatbot lives between those failures: it searches your own content, answers in two or three sentences, says "I don't know, want me to grab someone?" when it's unsure, and, the part everyone forgets, it turns a buying signal into a real meeting on someone's calendar. This is the engineer's playbook for building that on n8n, US-first, with export-ready JSON you can paste in and adapt.
We build these for US SMBs first, a Denver HVAC contractor, a Texas SaaS doing inbound support, a New York clinic answering insurance questions, and the same architecture ships to UK and European clients with the privacy controls swapped in, and to the occasional Australian client at the tail end. The stack doesn't change across regions. What changes is where the data lives and which law governs the transcript, and we'll get to that.
Model choice in 2026: it is not "OpenAI only" anymore
The single biggest change since this article first ran is that the model is now a swappable part, not a foundation you pour. n8n ships first-party chat-model nodes for all three major providers, and they drop into the same AI Agent or LLM Chain node interchangeably. Choosing well saves real money and real grief, so here is how we actually decide.
The answer model
OpenAI GPT-4o / GPT-4o-mini is the sane default: fast, cheap at the mini tier, and the broadest tooling. For a high-traffic FAQ bot where most questions are easy, gpt-4o-mini handles the bulk and you escalate only the hard ones to a bigger model. Anthropic's Claude (we reach for the Sonnet tier) is the one we pick when grounding discipline matters most, it is unusually good at actually obeying "answer only from the context below, and if it's not there, say so." For a chatbot that must not invent pricing or policy, that obedience is worth the slightly higher token price. Google's Gemini is the value play: competitive quality, aggressive pricing, and a very long context window if you want to stuff more retrieved chunks in. There is no universally correct answer, there is a correct answer for your traffic mix, and you should be able to A/B it by changing one node.
The embeddings model
Embeddings, the vectors that power retrieval, are a separate, cheaper decision from the answer model, and you do not have to match providers. OpenAI's text-embedding-3-small is the workhorse: 1,536 dimensions, pennies per million tokens, and good enough for almost every SMB knowledge base. Gemini and several open-source models (e.g. bge and nomic-embed families you can self-host) are viable if you want to keep embeddings off a US API entirely. The one hard rule: embed your documents and your queries with the same model. Mixing embedding models silently destroys retrieval quality because the vectors live in different spaces. Pick one, and if you ever change it, re-embed the whole corpus.
You can now let an assistant build the chatbot for you. Since April 2026, n8n ships a native, instance-level MCP server (Model Context Protocol), turn it on and a client like Claude Desktop, Claude Code, Cursor, or ChatGPT can assemble, test, and deploy these very workflows inside your n8n instance from a plain-English brief. It collapses the first draft of an ingest or chat pipeline from an afternoon to a sentence. The same protocol also lets your chatbot reach external tools (order status, a calendar, a CRM) as clean MCP endpoints instead of hand-wired integrations. We wrote the full playbook on it, see n8n + MCP in 2026, and it pairs directly with everything below.
The RAG architecture, end to end
RAG, Retrieval-Augmented Generation, is the reason a good chatbot answers your questions instead of generic web trivia. The flow is always the same: ingest your docs → chunk them → embed each chunk → store the vectors → retrieve the relevant ones at query time → hand them to the model as grounded context → answer. Two of those steps run offline on a schedule (ingest, chunk, embed, store); the rest run live on every message. Building them as two separate n8n workflows is the right call, they fail independently and you re-run ingest without touching the live bot.
Picking the vector store
| Store | Best for | Why we pick it |
|---|---|---|
| pgvector (Postgres) | Self-hosted, data stays in-house | One database for vectors and your app data; no extra vendor; the default for our local tier. |
| Qdrant | Speed at larger corpora | Purpose-built, fast filtering, easy to self-host alongside n8n. |
| Pinecone | Fully managed, zero ops | Nothing to run; good when the client has no infra appetite and accepts a US SaaS. |
For most US SMBs on our cloud tier we start with Pinecone or Qdrant Cloud because there's nothing to operate. For the local self-hosted tier we use pgvector almost every time, the chatbot's knowledge base and the customer's data live in one Postgres instance the client owns, which is both simpler and a cleaner privacy story.
Chunking: the unglamorous step that decides quality
Retrieval is only as good as your chunks. Too large and you bury the relevant sentence in noise the model has to wade through; too small and you sever the context a sentence needs to make sense. Our default is roughly 500–800 tokens per chunk with a 10–15% overlap, split on natural boundaries (headings, paragraphs) rather than blindly every N characters. Attach metadata to every chunk, source URL, page title, last-updated date, because that metadata is what you cite back to the visitor and what lets you filter retrieval (e.g. "only answer from the pricing and policy pages for billing questions").
Build 1: the ingest pipeline (n8n JSON)
This runs on a schedule. It fetches your sitemap, pulls each page, chunks the text, embeds the chunks, and upserts them into the vector store. Export-ready skeleton, swap the embeddings node and the store node for your chosen providers:
{
"name": "Chatbot — Ingest & Embed (RAG)",
"nodes": [
{
"parameters": {
"rule": { "interval": [{ "field": "days", "daysInterval": 1 }] }
},
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2,
"name": "Nightly Re-index",
"position": [200, 300]
},
{
"parameters": {
"url": "https://www.nex-flow.io/sitemap.xml",
"options": {}
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"name": "Fetch Sitemap",
"position": [420, 300]
},
{
"parameters": {
"fieldToSplitOut": "urlset.url",
"options": {}
},
"type": "n8n-nodes-base.splitOut",
"typeVersion": 1,
"name": "One Item Per URL",
"position": [620, 300]
},
{
"parameters": {
"url": "={{ $json.loc }}",
"options": { "response": { "response": { "responseFormat": "text" } } }
},
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"name": "Fetch Page HTML",
"position": [820, 300]
},
{
"parameters": {
"chunkSize": 700,
"chunkOverlap": 90
},
"type": "@n8n/n8n-nodes-langchain.textSplitterRecursiveCharacterTextSplitter",
"typeVersion": 1,
"name": "Chunk (700 / 90 overlap)",
"position": [1020, 460]
},
{
"parameters": {
"model": "text-embedding-3-small"
},
"type": "@n8n/n8n-nodes-langchain.embeddingsOpenAi",
"typeVersion": 1,
"name": "Embeddings (3-small)",
"position": [1020, 600]
},
{
"parameters": {
"mode": "insert",
"tableName": "kb_chunks",
"options": { "metadata": { "source_url": "={{ $json.loc }}" } }
},
"type": "@n8n/n8n-nodes-langchain.vectorStorePGVector",
"typeVersion": 1.1,
"name": "Upsert to pgvector",
"position": [1240, 300]
}
],
"connections": {
"Nightly Re-index": { "main": [[{ "node": "Fetch Sitemap", "type": "main", "index": 0 }]] },
"Fetch Sitemap": { "main": [[{ "node": "One Item Per URL", "type": "main", "index": 0 }]] },
"One Item Per URL": { "main": [[{ "node": "Fetch Page HTML", "type": "main", "index": 0 }]] },
"Fetch Page HTML": { "main": [[{ "node": "Upsert to pgvector", "type": "main", "index": 0 }]] },
"Chunk (700 / 90 overlap)": { "ai_textSplitter": [[{ "node": "Upsert to pgvector", "type": "ai_textSplitter", "index": 0 }]] },
"Embeddings (3-small)": { "ai_embedding": [[{ "node": "Upsert to pgvector", "type": "ai_embedding", "index": 0 }]] }
}
}A few production notes that aren't in the JSON. Strip nav, footer, and boilerplate before chunking, otherwise every chunk carries your menu and retrieval gets noisy. Stamp each chunk with a content hash so you only re-embed pages that actually changed (embeddings cost money on every run). Run ingest nightly, not hourly, your website does not change that fast, and you'll thank yourself on the API bill.
Build 2: the chat / answer pipeline (n8n JSON)
This is the live workflow. The widget POSTs the message, session ID, and page URL to an n8n webhook. n8n embeds the question, retrieves the top matching chunks, builds a grounded prompt, calls the LLM, and returns JSON. Here we use the Claude node for its grounding discipline, swap it for the OpenAI or Gemini node and nothing else changes:
{
"name": "Chatbot — Chat & Answer (RAG)",
"nodes": [
{
"parameters": {
"httpMethod": "POST",
"path": "site-chat",
"responseMode": "responseNode"
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2,
"name": "Chat Webhook",
"position": [200, 300]
},
{
"parameters": {
"mode": "retrieve-as-tool",
"tableName": "kb_chunks",
"topK": 5,
"toolDescription": "Search the NexFlow knowledge base for facts to answer the question."
},
"type": "@n8n/n8n-nodes-langchain.vectorStorePGVector",
"typeVersion": 1.1,
"name": "Retrieve Top 5",
"position": [440, 460]
},
{
"parameters": {
"model": "text-embedding-3-small"
},
"type": "@n8n/n8n-nodes-langchain.embeddingsOpenAi",
"typeVersion": 1,
"name": "Query Embeddings",
"position": [440, 600]
},
{
"parameters": {
"promptType": "define",
"text": "={{ $json.body.message }}",
"options": {
"systemMessage": "You are the NexFlow website assistant. Answer ONLY from the retrieved context. If the answer is not in the context, reply exactly: \"I'm not certain on that one — want me to put you in touch with the team?\" Keep answers to 2-3 sentences. Always end with the source_url of the chunk you used. Never invent pricing, guarantees, or policy."
}
},
"type": "@n8n/n8n-nodes-langchain.agent",
"typeVersion": 2,
"name": "Grounded Agent",
"position": [700, 300]
},
{
"parameters": {
"model": "claude-sonnet-4-5",
"options": { "temperature": 0.1 }
},
"type": "@n8n/n8n-nodes-langchain.lmChatAnthropic",
"typeVersion": 1,
"name": "Claude (grounding)",
"position": [700, 480]
},
{
"parameters": {
"respondWith": "json",
"responseBody": "={{ { \"answer\": $json.output, \"session\": $json.body.session, \"escalate\": $json.output.includes('put you in touch') } }}"
},
"type": "n8n-nodes-base.respondToWebhook",
"typeVersion": 1.1,
"name": "Respond JSON",
"position": [980, 300]
}
],
"connections": {
"Chat Webhook": { "main": [[{ "node": "Grounded Agent", "type": "main", "index": 0 }]] },
"Retrieve Top 5": { "ai_tool": [[{ "node": "Grounded Agent", "type": "ai_tool", "index": 0 }]] },
"Query Embeddings": { "ai_embedding": [[{ "node": "Retrieve Top 5", "type": "ai_embedding", "index": 0 }]] },
"Claude (grounding)": { "ai_languageModel": [[{ "node": "Grounded Agent", "type": "ai_languageModel", "index": 0 }]] },
"Grounded Agent": { "main": [[{ "node": "Respond JSON", "type": "main", "index": 0 }]] }
}
}
Keep the response shape boring and stable: answer, session, escalate, and optionally a source_url the widget can render as a "from our pricing page" link. The widget doesn't need to know which model produced the answer, that's the point of orchestrating it in n8n.
Grounding, hallucination control, and latency
The system message above is doing most of the safety work, but grounding is a layered discipline, not one clever instruction. Here is the stack we ship.
Refuse, don't guess
The model must be told, explicitly, in the system prompt, to answer only from retrieved context and to produce a specific "I don't know" sentence when the context doesn't contain the answer. We make that refusal sentence a fixed string so the widget can detect it and offer a human handoff. A bot that says "I'm not certain, want me to grab someone?" feels honest; a bot that confidently invents an answer destroys trust the first time a customer checks it.
Score thresholds and citations
Retrieval returns a similarity score with every chunk. Set a floor, if the best match is below it, treat the question as out of scope and refuse rather than feeding weak context to the model (weak context is where confident nonsense comes from). And cite: return the source_url of the chunk you used so the answer is checkable. Internally, log which chunks were retrieved for each turn; when the bot gets something wrong, the log tells you instantly whether retrieval missed or the model ignored good context.
Answer only from approved website, pricing, policy, and support content. Never invent case studies, guarantees, discounts, or legal/medical/financial advice. Refuse and escalate on complaints, security issues, regulated data, and anything ambiguous. Keep temperature at or below 0.2 so the model doesn't get creative with facts. Cap conversation history (summarise older turns) so prompts stay short. And test the whole thing with a list of adversarial questions, "give me a discount code", "what's your cancellation policy" when you have none, before it touches a real visitor.
Latency you can defend
A credible target is under two seconds for a normal answer. Vector search should be under 200 ms; prompt assembly under 100 ms. The model call is the dominant cost and latency driver. If answers regularly cross three seconds, the levers are: retrieve fewer chunks (top-5 is plenty for most sites), shorten the system prompt, summarise history instead of replaying it, and, the big one, use a faster, smaller model (gpt-4o-mini, Claude Haiku, Gemini Flash) for the first response and reserve the heavyweight model for genuinely hard questions. Streaming the response token-by-token to the widget also makes a 2.5-second answer feel instant, because the visitor sees words appearing immediately.
The conversion point: lead capture and booking a real call
Here is where most chatbot projects fail to pay for themselves: they answer questions beautifully and then let the interested visitor wander off. The ROI is not in the answers, it's in catching the moment of intent and converting it. When the conversation shows buying signals ("how much", "can you do X for my business", "how do I get started"), the chat pipeline should pivot: ask for an email in-conversation, write the contact plus the full transcript to your CRM or database, and return a real scheduling link so the visitor books a call without leaving the chat.
Mechanically, this is one more branch in the chat workflow. An intent check (a cheap classifier or a keyword/score heuristic) flips an escalate or book flag. On book, n8n upserts the contact to your CRM, posts a Slack/Telegram alert to the team with the transcript and a one-line summary, and the widget renders a Cal.com or Calendly embed seeded with the visitor's email. The booked meeting is the conversion you report on, sessions and message counts are vanity numbers next to it. Tie every booking back to the chat session ID so you can prove the bot's pipeline contribution, not just guess at it.
A good handoff packet, whether to a human or a calendar, includes the visitor's email if given, the page URL, the full transcript, a one-line summary, the detected intent, and urgency. The visitor should see a plain confirmation ("You're booked for Thursday 2pm, calendar invite is on its way"), never a vague "someone will be in touch."
Privacy & compliance: US first, then UK/EU
A chat transcript is personal information. Treat it like one from day one. In the US, the CCPA and its expansion the CPRA treat a transcript tied to an email or device as personal information a California consumer can ask you to disclose or delete, and the wave of state privacy laws (Virginia, Colorado, Texas, and more) reach the same conclusion. Practical moves: post a short notice that the chat is recorded and may train nothing (use a model vendor with a no-training term), give a way to delete a session, and don't secretly pipe transcripts to a third party you haven't disclosed.
For UK and EU visitors, the UK GDPR and EU GDPR add a lawful-basis and cross-border-transfer layer: sending a transcript to a US-hosted model is an international transfer under GDPR Chapter V, so prefer a vendor with EU data residency or self-host the model, and from 2 August 2026 the EU AI Act's Article 50 transparency duty means you must tell users they're talking to an AI. (Australia's Privacy Act and APP 8 reward the same self-host-and-disclose pattern, a one-line note for the rare AU build.) The clean architecture that satisfies all of them is the local self-hosted tier: keep the vector store and ideally the model on infrastructure you own, and the transcript never leaves your walls in the first place.
- RAG beats both canned-script bots and ungrounded LLMs for any business site, answer from your own content or don't answer.
- Build it as two n8n workflows: a scheduled ingest/embed pipeline and a live chat/answer pipeline. They fail independently.
- You are not locked to OpenAI, GPT-4o, Claude, and Gemini all drop into the same n8n node; pick per job, and let the new native MCP server help you build it.
- Embed documents and queries with the same model; mixing embedding models silently wrecks retrieval.
- Grounding is a stack: refuse-don't-guess, score thresholds, citations, low temperature, and adversarial testing before launch.
- The conversion is the booked call, not the chat, capture the lead and put a real scheduling link in the conversation.
- A transcript is personal info: CCPA/CPRA first, then UK/EU GDPR (and the AU Privacy Act). Self-hosting keeps it in-house.
A one-week rollout
- Day 1, scope the sources. Decide exactly which pages and docs the bot may answer from. Coverage gaps now become "I don't know" later.
- Day 2, stand up the store and ingest. Pick pgvector, Qdrant, or Pinecone; build the ingest workflow; run it once and spot-check a few chunks for clean text.
- Day 3, wire the chat pipeline. Webhook → retrieve → grounded agent → respond. Pick your answer and embeddings models. Test with real questions.
- Day 4, harden grounding. Add the refusal string, the score threshold, citations, and low temperature. Run your adversarial question list and fix every confident wrong answer.
- Day 5, add the conversion path. Intent check → email capture → CRM write → scheduling link. Confirm a booking lands on the calendar end to end.
- Day 6, privacy & logging. Add the recording notice, a delete path, and a transcript log. Decide where the data lives.
- Day 7, measure. Wire booked calls back to chat session IDs so you can report pipeline, not just message counts. Ship.
Custom workflow (cloud), from $750. We build it on your existing n8n Cloud, Zapier, or Make plan, so you keep your current subscriptions. Best when you want one job automated fast, under $1,000.
Local self-hosted setup, from $1,500 one-off. We stand n8n up on infrastructure you own, port the workflows across, and retire the monthly SaaS subscriptions entirely. Self-hosting is the premium tier, it runs above $1,000 precisely because it removes the recurring fees and keeps your data (and your customers' chat transcripts) in-house.
Want a chatbot that books real calls?
Book a 15-minute map and we'll scope your sources, models, guardrails, and the conversion path before a line is built. From there it's one of two tiers: a custom cloud workflow from $750 on the stack you already pay for, or a local self-hosted build from $1,500 one-off that retires the subscriptions and keeps every transcript in-house. You leave the map knowing exactly which one fits and what it answers.
Sources & method
- Architecture, chunking defaults, and latency/cost targets from NexFlow chatbot and RAG builds for US, UK, and EU SMB websites, Q1–Q2 2026, validate under your own traffic before launch.
- Model nodes, n8n built-in OpenAI, Anthropic (Claude), and Google Gemini chat-model and embeddings nodes; native instance-level MCP server (Public Preview, April 2026). See our n8n + MCP playbook.
- Vector stores, pgvector (Postgres extension), Qdrant, and Pinecone; choose on ops appetite and data-residency needs.
- Model behaviour, context windows, and pricing should be checked against current OpenAI, Anthropic, and Google documentation before deployment.
- Privacy, US CCPA/CPRA and state privacy laws (transcripts as personal information); UK/EU GDPR Chapter V cross-border transfers; EU AI Act Article 50 transparency (enforceable 2 Aug 2026); Australia's Privacy Act / APP 8 noted as an additional regime.